This is the second part of my ? part series on the implementation of submanifold convolution. Here, we will discuss about the implementation of a hash table on the GPU. The entire codebase can be found here.
Before we continue, let us set some notations.
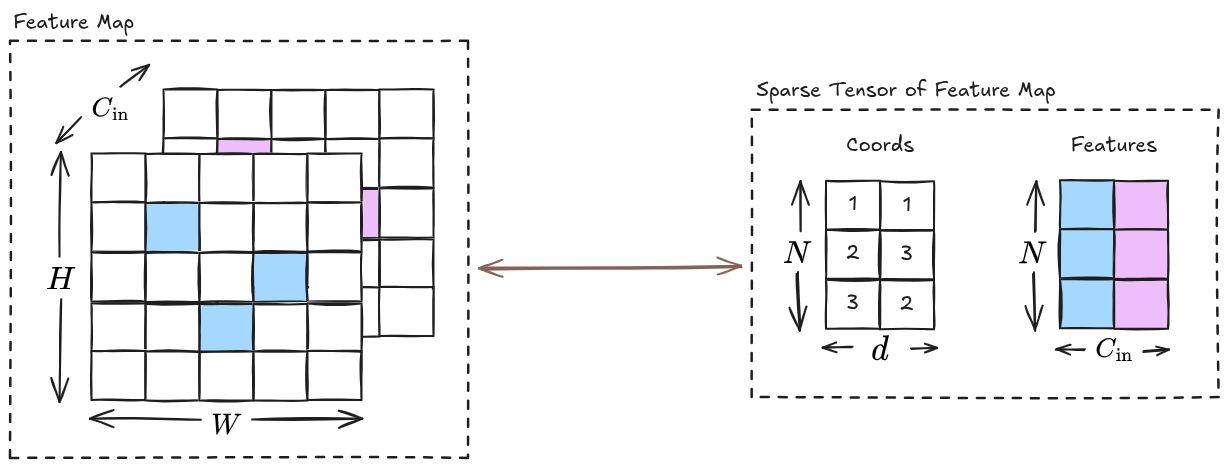
Let
Hash Table
A hash table is a data structure that stores items as unique key-value pairs. We require a hash table to efficiently fetch the neighbors of
With some mathematics, we can find the neighbors of
The flattened index correponding to
Thus, we will use
Why GPU?
In practical applications, there can be large number of elements in the sparse tensor. If we want to create a hash table in a CPU, then the insertions and lookups need to be performed sequentially (assuming that no parallel processing is done). However, if we use a GPU for this purpose, then we can perform insertions and lookups in bulk, which increases efficiency.
The Hash Function
As we know, we require a hash function to compute the slot in the hash table from the key. This slot will hold both the key and the value.
For our implementation, we will follow the references and use the “finalize” part of the MurmurHash3:
// 32 bit Murmur3 hash
__forceinline__ __device__ size_t hash(uint32_t k, size_t N) {
k ^= k >> 16;
k *= 0x85ebca6b;
k ^= k >> 13;
k *= 0xc2b2ae35;
k ^= k >> 16;
return k % N;
}
// 64 bit Murmur3 hash
__forceinline__ __device__ size_t hash(uint64_t k, size_t N) {
k ^= k >> 33;
k *= 0xff51afd7ed558ccdULL;
k ^= k >> 33;
k *= 0xc4ceb9fe1a85ec53ULL;
k ^= k >> 33;
return k % N;
}Initialization
We assume the following factors about the initialization of the hash table:
- All keys are initialized to the maximum value that the data type of the key can represent.
- All values are initialized to be empty.
- The size of the hash table is given by
.
Insertion
The code to insert the key-value pairs in the hash table is as follows:
template<typename V>
__forceinline__ __device__ void linear_probing_insert(
uint64_t* hashmap_keys,
V* hashmap_values,
const uint64_t key,
const V value,
const size_t N
) {
size_t slot = hash(key, N);
while (true) {
uint64_t prev = atomicCAS(
reinterpret_cast<unsigned long long*>(&hashmap_keys[slot]),
static_cast<unsigned long long>(std::numeric_limits<uint64_t>::max()),
static_cast<unsigned long long>(key)
);
if (prev == std::numeric_limits<uint64_t>::max() || prev == key) {
hashmap_values[slot] = value;
return;
}
slot = (slot + 1) % N;
}
}In the above code, we do the following:
- We compute a slot in the hash table from the key,
, using the hash function. - We perform atomic compare-and-swap operation i.e.
- we compare the existing key in the slot,
, with the maximum value, , and - if it matches then we replace the value with the key, and return the replaced value,
, - otherwise we just return the maximum value,
.
- we compare the existing key in the slot,
- If the result from the atomic compare-and-swap operation matches the key or the maximum value, then we insert the value in that slot, otherwise we repeat from step 2 after performing linear probing.
Lookup
The code to lookup the value at a key in the hast table is as follows:
template<typename K, typename V>
__forceinline__ __device__ V linear_probing_lookup(
const K* hashmap_keys,
const V* hashmap_values,
const K key,
const size_t N
) {
size_t slot = hash(key, N);
while (true) {
K prev = hashmap_keys[slot];
if (prev == std::numeric_limits<K>::max()) {
return std::numeric_limits<V>::max();
}
if (prev == key) {
return hashmap_values[slot];
}
slot = slot + 1;
if (slot >= N) slot = 0;
}
}In the above code, we do the following:
- We compute the slot in the hash table for the key,
, using the hash function. - We compare the key at the slot,
, with the maximum value, , and if it matches then we return . - Otherwise, we compare
with , and if it matches then we return the value at the slot. - Otherwise, we increment the slot, and repeat from step 2. Note that we set the slot to 0 if it exceeds the size of the hash table.
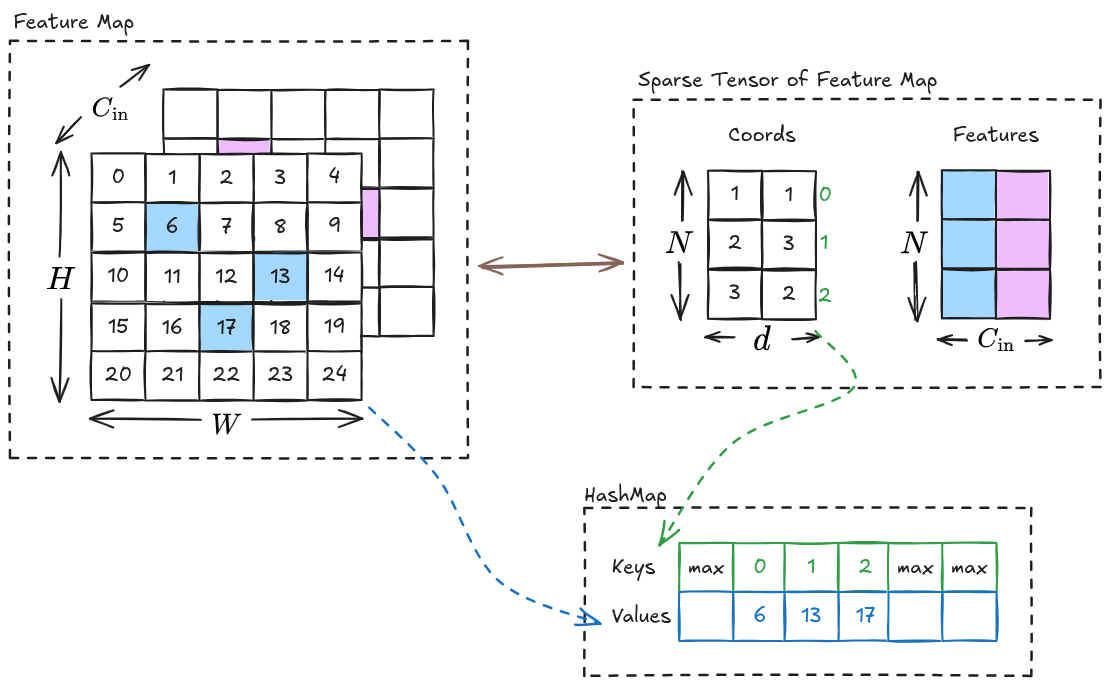
Inserting 2D Index as Value
The kernel for inserting the
template<typename K, typename V>
static __global__ void hashmap_insert_2d_idx_as_val_cuda_kernel(
const size_t N,
const size_t M,
int W, int H,
K* __restrict__ hashmap_keys,
V* __restrict__ hashmap_values,
const int32_t* __restrict__ keys
) {
size_t thread_id = blockIdx.x * blockDim.x + threadIdx.x;
if (thread_id < M) {
int3 coord = reinterpret_cast<const int3*>(keys)[thread_id];
int b = coord.x; // batch
int x = coord.y;
int y = coord.z;
size_t flat_idx = (size_t)b * W * H + (size_t)x * H + y;
K key = static_cast<K>(flat_idx);
V value = static_cast<V>(thread_id);
linear_probing_insert(hashmap_keys, hashmap_values, key, value, N);
}
}In the above code, we do the following:
- Compute the
thread_id, which is corresponding torow index in . - Use the
thread_idto obtain. - Obtain
from . - Insert
as row-value pair in the hash table.
Inserting 3D Index as Value
The above code works for feature maps with two spatial dimensions (width and height), but it can be easily extended to feature maps with three spatial dimensions (width, height and depth) as follows:
template<typename K, typename V>
static __global__ void hashmap_insert_3d_idx_as_val_cuda_kernel(
const size_t N,
const size_t M,
int W, int H, int D,
K* __restrict__ hashmap_keys,
V* __restrict__ hashmap_values,
const int32_t* __restrict__ keys
) {
const size_t thread_id = blockIdx.x * blockDim.x + threadIdx.x;
if (thread_id < M) {
int4 coord = reinterpret_cast<const int4*>(keys)[thread_id];
int b = coord.x; // batch
int x = coord.y;
int y = coord.z;
int z = coord.w;
size_t flat_idx = (size_t)b * W * H * D + (size_t)x * H * D + (size_t)y * D + z;
K key = static_cast<K>(flat_idx);
V value = static_cast<V>(thread_id);
linear_probing_insert(hashmap_keys, hashmap_values, key, value, N);
}
}References
Contents